My Junior SRP Project
Presentation
Abstract
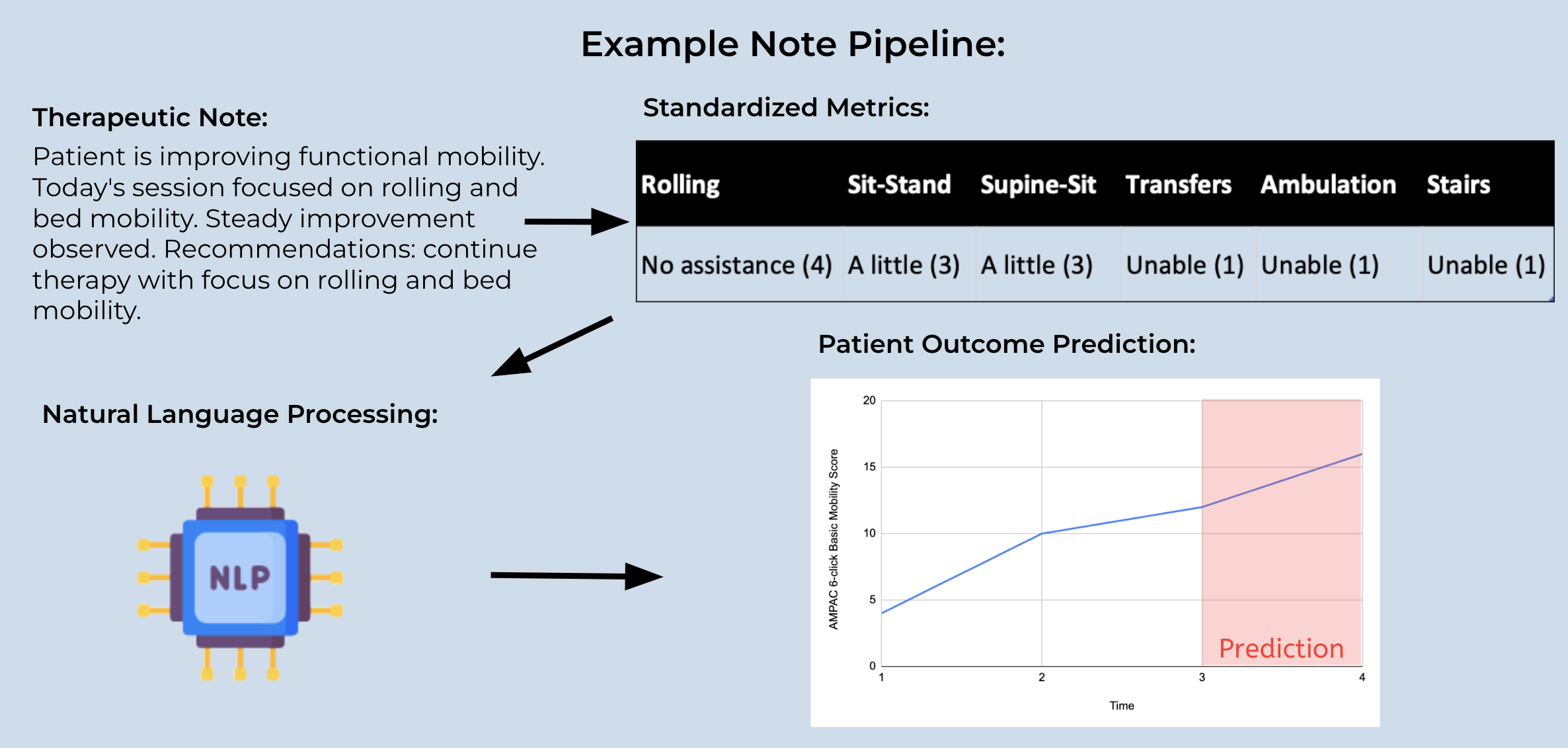
An increasing amount of crucial information is stored in Electronic Health Records (EHRs). Therapeutic records often contain unstructured free text, making labeling and processing time-consuming, while the insights labeled data provides are immense. Natural language processing models are growing in clinical practice and are already used to identify disease onset and medication information from clinical notes. One specific NLP model, BERT, has been trained on other language datasets (giving a greater understanding of words and their relationships), allowing us to extract desired values from therapeutic note language. This study employs Natural Language Processing (NLP) to extract standardized clinical scales from therapeutic EHRs, aiming to build a tool for predicting and tracking patient outcomes from note histories. We exported, deidentified, and labeled a random subset of clinical notes from the Massachusetts General Hospital provider network using the AM-PAC 6 click score (for functional mobility), modified Rankin score (for daily living activities), Glasgow Coma Scale Verbal Score (for consciousness after injury/trauma), and the IDDSI Food Consistency Framework (for food and liquid swallowing capabilities). We then used the BERT transformer model to automate the labeling of these notes. We generated one NLP model for each metric, which was determined to be optimal for generating the appropriate standardized metric from therapeutic notes. The final models had an 83% validation accuracy, indicating the automation of standardization of notes is feasible. Implementing this model will provide numerical data for each therapeutic note, allowing us to work towards the final goal of predicting therapeutic patient outcomes.
Introduction
Problem:
- Valuable information about patient health status are unanalyzable due to being in textual format in Electronic Health Records (EHRs)
Therapeutic Notes:
- Contains information about patients assessed abilities
- Written by therapist after seeing patient
Standardized Metrics:
- Allow for documentation and tracking of therapeutic progress
- Each therapeutic discipline has established metrics, but many therapists do not use these metrics regularly to track ongoing care and outcomes
BERT:
- Helps machines understand the meaning of words in context by analyzing text in its entirety
- Is a machine learning encoder model that converts strings of words into a large vector output
- A Convolutional Neural Network is used to convert the large vector output of BERT into the desired metric
Methods
- Exported and deidentified therapeutic notes from the Massachusetts General Hospital provider network
- Categorized notes into Physical Therapy (PT, n=30), Occupational Therapy (OT, n=14), and Speech and Language Therapy (SLT, n=19)
- Manually labeled each note, using the subfield specific metric
- Data was imported into python
- Each metric was split to create one model per metric
- Data was used to train Convolutional Neural Networks with BERT processing layer (Fig 3)
- Data was split into training and testing categories, 60/40 split
- Early stopping was utilized to avoid model overfitting, with a patience of 5 epochs
- Accuracy and loss were measured and graphed (Fig 5)
Results
- The machine learning models for Rolling, Supine Sit, Transfers, and Ambulation were all 83.3% accurate on validation data
- Training accuracy consistently improves, and training loss decreases across all models, indicating that the models are learning effectively from the training data.
Conclusions
Limitations:
- Some models exhibit a significant gap between training and validation performance (e.g., high training accuracy but low validation accuracy, and increasing validation loss). This suggests overfitting
- A 100% validation accuracy on the Stairs model suggests the validation dataset is too small, unrepresentative, or overlaps with the training data.
- A larger dataset would provide for a much more generalizable model, so as to avoid overfitting, bias, and poor generalization to unseen data
Next Steps:
- Create a new PT metric model featuring significantly more data
- Use the findings from this section of the study to influence programming decisions while building the OT and SLT models
- The final NLP models can process a larger set of medical records, converting each note to its numeric values, allowing for datasets to be analyzed longitudinally to assess patient progress.
- This approach has the potential to inform clinical decisions without provider bias and forecast disease progression
Figures:

Figure 1: Therapy and description of associated standardized metrics (created by student researcher)
Figure 2: A flowchart of note processing (created by student researcher)
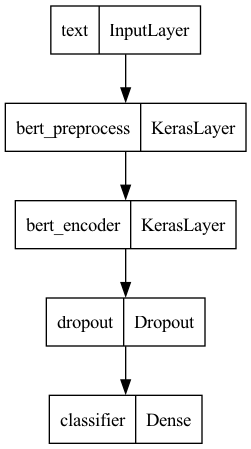
Figure 3: The Natural Language Processing architecture (created by student researcher)
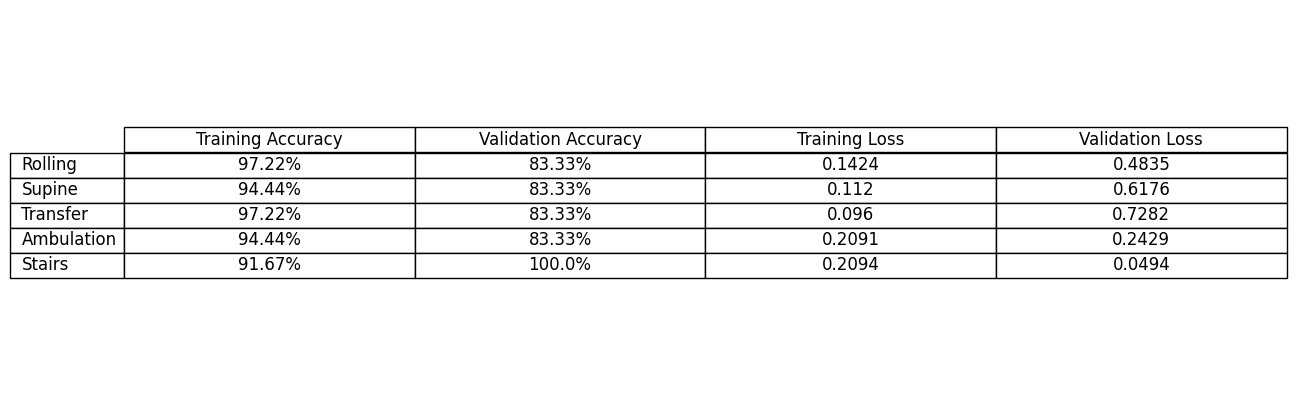
Figure 4: Final PT model evaluation metrics (created by student researcher)
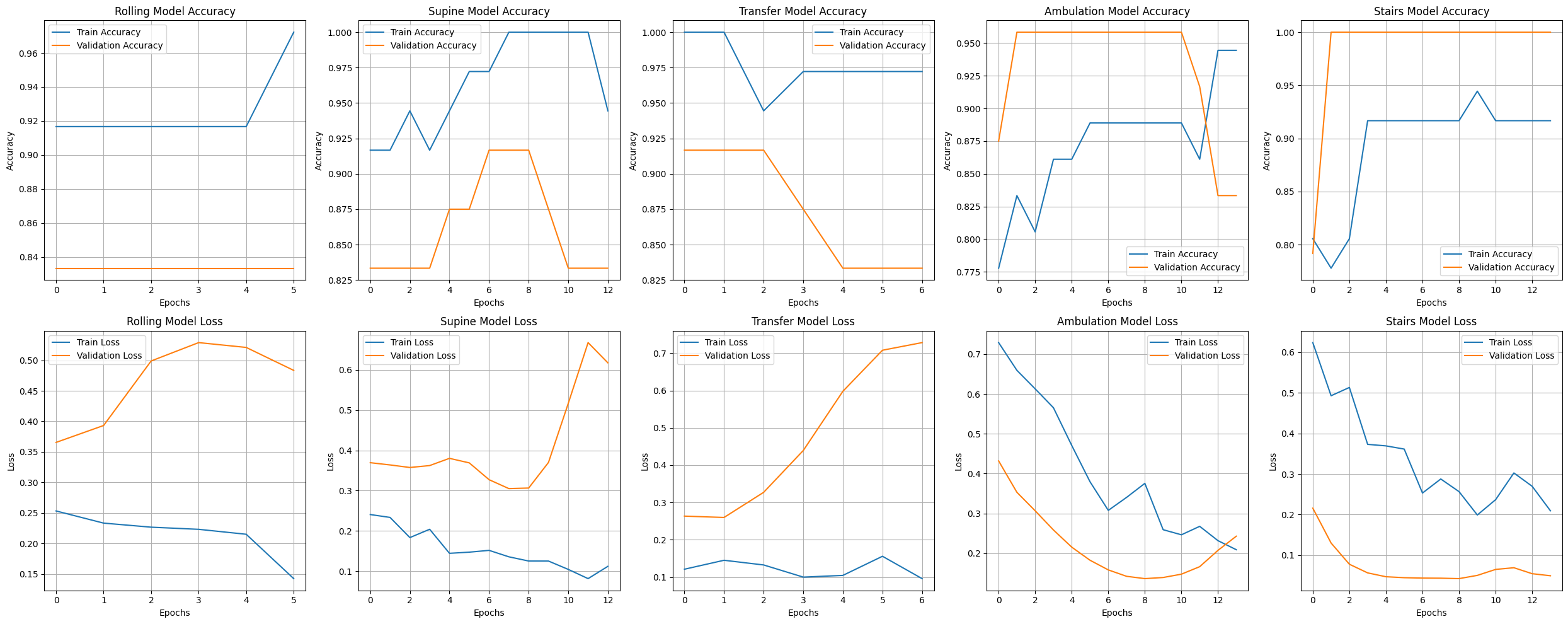
Figure 5: PT model evaluation over time (created by student researcher)